
除了線性代數之外,概率論也是人工智慧研究中必備的數學基礎,隨著連接主義學派的興起,概率統計已經取代了數理邏輯,成為人工智慧研究的主流工具,在數據爆炸式增長和計算力指數化增強的今天,概率論已經在機器學習中扮演了核心角色
同線性代數一樣,概率論也代表了一種看待世界的方式,其關注的焦點是無處不在的可能性,對隨機事件發生的可能性進行規範的數學描述就是概率論的公理化過程,概率的公理化結構體現出的是對概率本質的一種認識
將同一枚硬幣拋擲 10 次,其正面朝上的次數既可能一次沒有,也可能全部都是,換算成頻率就分別對應著 0% 和 100%,頻率本身顯然會隨機波動,但隨著重復試驗的次數不斷增加,特定事件出現的頻率值就會呈現出穩定性,逐漸趨近於某個常數
從事件發生的頻率認識概率的方法被稱為「頻率學派」,頻率學派口中的「概率」,其實是一個可獨立重復的隨機實驗中單個結果出現頻率的極限,因為穩定的頻率是統計規律性的體現,因而通過大量的獨立重復試驗計算頻率,並用它來表徵事件發生的可能性是一種合理的思路
在概率的定量計算上,頻率學派依賴的基礎是古典概率模型,在古典概率模型中,試驗的結果只包含有限個基本事件,且每個基本事件發生的可能性相同如此一來,假設所有基本事件的數目為 n,待觀察的隨機事件 A 中包含的基本事件數目為 k,則古典概率模型下事件概率的計算公式為 :
同線性代數一樣,概率論也代表了一種看待世界的方式,其關注的焦點是無處不在的可能性,對隨機事件發生的可能性進行規範的數學描述就是概率論的公理化過程,概率的公理化結構體現出的是對概率本質的一種認識
將同一枚硬幣拋擲 10 次,其正面朝上的次數既可能一次沒有,也可能全部都是,換算成頻率就分別對應著 0% 和 100%,頻率本身顯然會隨機波動,但隨著重復試驗的次數不斷增加,特定事件出現的頻率值就會呈現出穩定性,逐漸趨近於某個常數
從事件發生的頻率認識概率的方法被稱為「頻率學派」,頻率學派口中的「概率」,其實是一個可獨立重復的隨機實驗中單個結果出現頻率的極限,因為穩定的頻率是統計規律性的體現,因而通過大量的獨立重復試驗計算頻率,並用它來表徵事件發生的可能性是一種合理的思路
在概率的定量計算上,頻率學派依賴的基礎是古典概率模型,在古典概率模型中,試驗的結果只包含有限個基本事件,且每個基本事件發生的可能性相同如此一來,假設所有基本事件的數目為 n,待觀察的隨機事件 A 中包含的基本事件數目為 k,則古典概率模型下事件概率的計算公式為 :
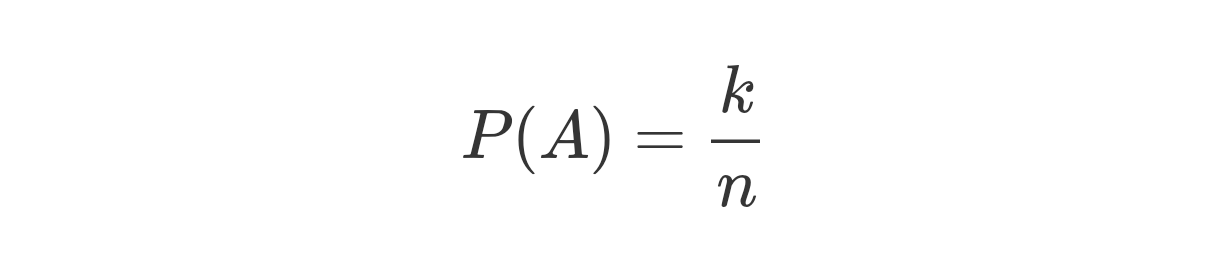
從這一基本公式就可以推導出複雜的隨機事件的概率
前文中的概率定義針對都是單個隨機事件,可如果要刻畫兩個隨機事件之間的關係,這個定義就不夠看了,在一場足球比賽中,球隊 1:0 取勝和在 0:2 落後的情況下 3:2 翻盤的概率顯然是不一樣的,這就需要引入條件概率的概念
條件概率是根據已有信息對樣本空間進行調整後得到的新的概率分布,假定有兩個隨機事件 A 和 B,條件概率就是指事件 A 在事件 B 已經發生的條件下發生的概率,用以下公式表示
前文中的概率定義針對都是單個隨機事件,可如果要刻畫兩個隨機事件之間的關係,這個定義就不夠看了,在一場足球比賽中,球隊 1:0 取勝和在 0:2 落後的情況下 3:2 翻盤的概率顯然是不一樣的,這就需要引入條件概率的概念
條件概率是根據已有信息對樣本空間進行調整後得到的新的概率分布,假定有兩個隨機事件 A 和 B,條件概率就是指事件 A 在事件 B 已經發生的條件下發生的概率,用以下公式表示
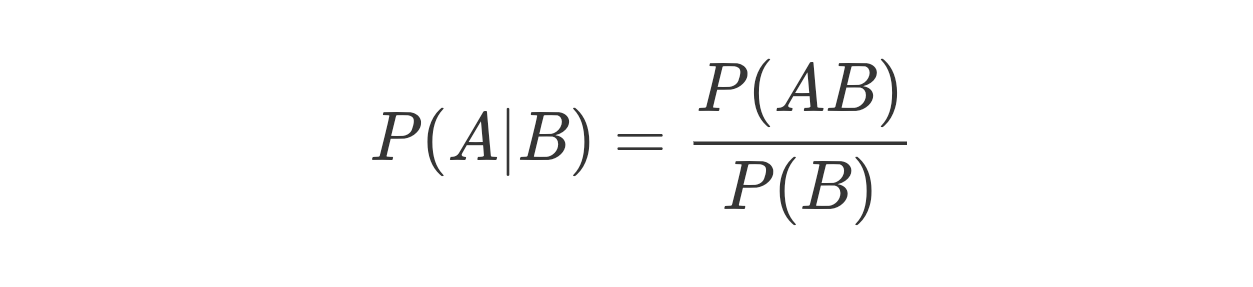
上式中的 P(AB) 稱為聯合概率,表示的是 A 和 B 兩個事件共同發生的概率,如果聯合概率等於兩個事件各自概率的乘積,即 P(AB)=P(A)⋅P(B),說明這兩個事件的發生互不影響,即兩者相互獨立,對於相互獨立的事件,條件概率就是自身的概率,即 P(A|B)=P(A)
基於條件概率可以得出全概率公式,全概率公式的作用在於將複雜事件的概率求解轉化為在不同情況下發生的簡單事件的概率求和,即
基於條件概率可以得出全概率公式,全概率公式的作用在於將複雜事件的概率求解轉化為在不同情況下發生的簡單事件的概率求和,即
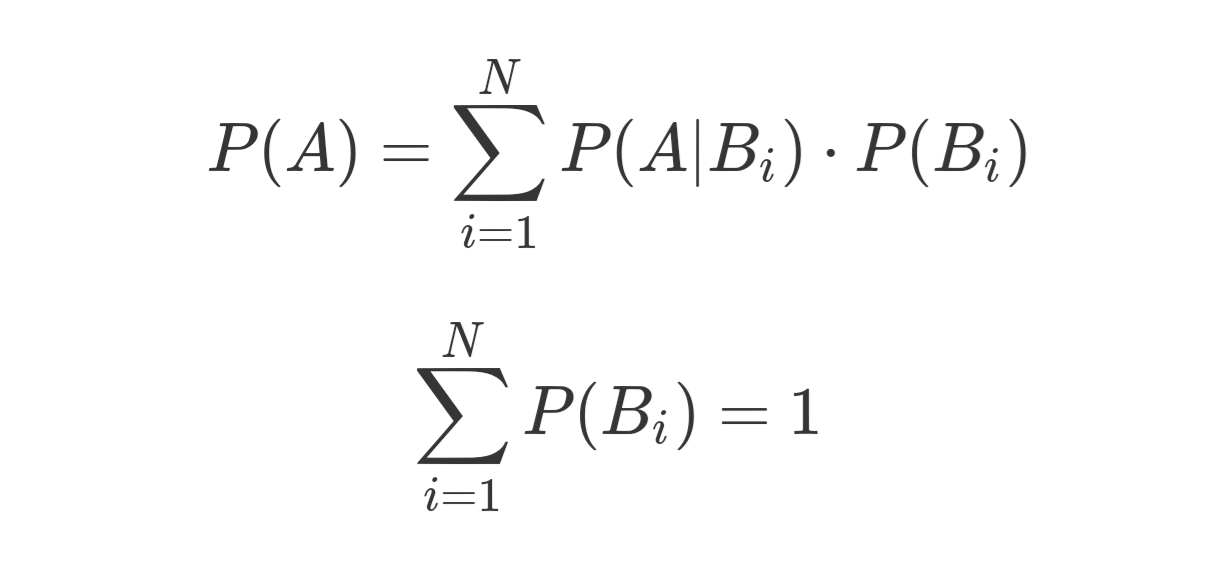
全概率公式代表了頻率學派解決概率問題的思路,即先做出一些假設(P(Bi)),再在這些假設下討論隨機事件的概率(P(A|Bi))
對全概率公式稍作整理,就演化出了求解「逆概率」這一重要問題,所謂「逆概率」解決的是在事件結果已經確定的條件下(P(A)),推斷各種假設發生的可能性(P(Bi|A)),由於這套理論首先由英國牧師托馬斯·貝葉斯提出,因而其通用的公式形式被稱為貝葉斯公式:
對全概率公式稍作整理,就演化出了求解「逆概率」這一重要問題,所謂「逆概率」解決的是在事件結果已經確定的條件下(P(A)),推斷各種假設發生的可能性(P(Bi|A)),由於這套理論首先由英國牧師托馬斯·貝葉斯提出,因而其通用的公式形式被稱為貝葉斯公式:
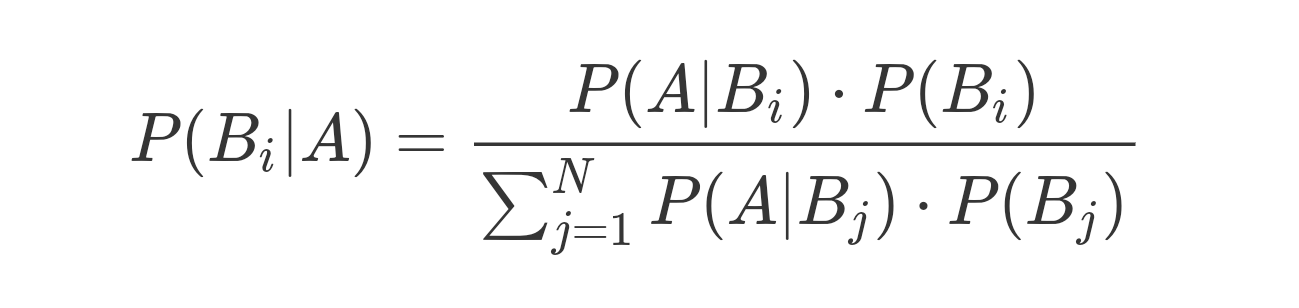
貝葉斯公式可以進一步抽象為貝葉斯定理:

公式中的 P(H) 被稱為先驗概率,即預先設定的假設成立的概率;P(D|H) 被稱為似然概率,是在假設成立的前提下觀測到結果的概率;P(H|D) 被稱為後驗概率,即在觀測到結果的前提下假設成立的概率
從科學研究的方法論來看,貝葉斯定理提供了一種全新的邏輯,它根據觀測結果尋找合理的假設,或者說根據觀測數據尋找最佳的理論解釋,其關注的焦點在於後驗概率,概率論的貝葉斯學派正是誕生於這種理念
在貝葉斯學派眼中,概率描述的是隨機事件的可信程度,如果手機里的天氣預報應用給出明天下雨的概率是 85%,這就不能從頻率的角度來解釋了,而是意味著明天下雨這個事件的可信度是 85%
頻率學派認為假設是客觀存在且不會改變的,即存在固定的先驗分布,只是作為觀察者無從知曉,因而在計算具體事件的概率時,要先確定概率分布的類型和參數,以此為基礎進行概率推演
相比之下,貝葉斯學派則認為固定的先驗分布是不存在的,參數本身也是隨機,換言之,假設本身取決於觀察結果,是不確定並且可以修正的,數據的作用就是對假設做出不斷的修正,使觀察者對概率的主觀認識更加接近客觀實際
概率論是線性代數之外,人工智慧的另一個理論基礎,多數機器學習模型採用的都是基於概率論的方法,但由於實際任務中可供使用的訓練數據有限,因而需要對概率分布的參數進行估計,這也是機器學習的核心任務
概率的估計有兩種方法:最大似然估計法和最大後驗概率法,兩者分別體現出頻率學派和貝葉斯學派對概率的理解方式
最大似然估計法的思想是使訓練數據出現的概率最大化,依此確定概率分布中的未知參數,估計出的概率分布也就最符合訓練數據的分布,最大後驗概率法的思想則是根據訓練數據和已知的其他條件,使未知參數出現的可能性最大化,並選取最可能的未知參數取值作為估計值,在估計參數時,最大似然估計法只需要使用訓練數據,最大後驗概率法除了數據外還需要額外的信息,就是貝葉斯公式中的先驗概率
從理論的角度來說,頻率學派和貝葉斯學派各有千秋,都發揮著不可替代的作用,但具體到人工智慧這一應用領域,基於貝葉斯定理的各種方法與人類的認知機制吻合度更高,在機器學習等領域中也扮演著更加重要的角色
概率論的一個重要應用是描述隨機變量,根據取值空間的不同,隨機變量可以分成兩類:離散型隨機變量和連續型隨機變量,在實際應用中,需要對隨機變量的每個可能取值的概率進行描述
離散變量的每個可能的取值都具有大於 0 的概率,取值和概率之間一一對應的關係就是離散型隨機變量的分布律,也叫概率質量函數,概率質量函數在連續型隨機變量上的對應就是概率密度函數
需要說明的是,概率密度函數體現的並非連續型隨機變量的真實概率,而是不同取值可能性之間的相對關係,對連續型隨機變量來說,其可能取值的數目為不可列無限個,當歸一化的概率被分配到這無限個點上時,每個點的概率都是個無窮小量,取極限的話就等於零,而概率密度函數的作用就是對這些無窮小量加以區分,雖然在 x→∞ 時,1/x 和 2/x 都是無窮小量,但後者永遠是前者的 2 倍,這類相對意義而非絕對意義上的差別就可以被概率密度函數所刻畫,對概率密度函數進行積分,得到的才是連續型隨機變量的取值落在某個區間內的概率
定義了概率質量函數與概率密度函數後,就可以給出一些重要分布的特性,重要的離散分布包括兩點分布、二項分布和泊松分布,重要的連續分布則包括均勻分布、指數分布和正態分布
從科學研究的方法論來看,貝葉斯定理提供了一種全新的邏輯,它根據觀測結果尋找合理的假設,或者說根據觀測數據尋找最佳的理論解釋,其關注的焦點在於後驗概率,概率論的貝葉斯學派正是誕生於這種理念
在貝葉斯學派眼中,概率描述的是隨機事件的可信程度,如果手機里的天氣預報應用給出明天下雨的概率是 85%,這就不能從頻率的角度來解釋了,而是意味著明天下雨這個事件的可信度是 85%
頻率學派認為假設是客觀存在且不會改變的,即存在固定的先驗分布,只是作為觀察者無從知曉,因而在計算具體事件的概率時,要先確定概率分布的類型和參數,以此為基礎進行概率推演
相比之下,貝葉斯學派則認為固定的先驗分布是不存在的,參數本身也是隨機,換言之,假設本身取決於觀察結果,是不確定並且可以修正的,數據的作用就是對假設做出不斷的修正,使觀察者對概率的主觀認識更加接近客觀實際
概率論是線性代數之外,人工智慧的另一個理論基礎,多數機器學習模型採用的都是基於概率論的方法,但由於實際任務中可供使用的訓練數據有限,因而需要對概率分布的參數進行估計,這也是機器學習的核心任務
概率的估計有兩種方法:最大似然估計法和最大後驗概率法,兩者分別體現出頻率學派和貝葉斯學派對概率的理解方式
最大似然估計法的思想是使訓練數據出現的概率最大化,依此確定概率分布中的未知參數,估計出的概率分布也就最符合訓練數據的分布,最大後驗概率法的思想則是根據訓練數據和已知的其他條件,使未知參數出現的可能性最大化,並選取最可能的未知參數取值作為估計值,在估計參數時,最大似然估計法只需要使用訓練數據,最大後驗概率法除了數據外還需要額外的信息,就是貝葉斯公式中的先驗概率
從理論的角度來說,頻率學派和貝葉斯學派各有千秋,都發揮著不可替代的作用,但具體到人工智慧這一應用領域,基於貝葉斯定理的各種方法與人類的認知機制吻合度更高,在機器學習等領域中也扮演著更加重要的角色
概率論的一個重要應用是描述隨機變量,根據取值空間的不同,隨機變量可以分成兩類:離散型隨機變量和連續型隨機變量,在實際應用中,需要對隨機變量的每個可能取值的概率進行描述
離散變量的每個可能的取值都具有大於 0 的概率,取值和概率之間一一對應的關係就是離散型隨機變量的分布律,也叫概率質量函數,概率質量函數在連續型隨機變量上的對應就是概率密度函數
需要說明的是,概率密度函數體現的並非連續型隨機變量的真實概率,而是不同取值可能性之間的相對關係,對連續型隨機變量來說,其可能取值的數目為不可列無限個,當歸一化的概率被分配到這無限個點上時,每個點的概率都是個無窮小量,取極限的話就等於零,而概率密度函數的作用就是對這些無窮小量加以區分,雖然在 x→∞ 時,1/x 和 2/x 都是無窮小量,但後者永遠是前者的 2 倍,這類相對意義而非絕對意義上的差別就可以被概率密度函數所刻畫,對概率密度函數進行積分,得到的才是連續型隨機變量的取值落在某個區間內的概率
定義了概率質量函數與概率密度函數後,就可以給出一些重要分布的特性,重要的離散分布包括兩點分布、二項分布和泊松分布,重要的連續分布則包括均勻分布、指數分布和正態分布
● 兩點分布:適用於隨機試驗的結果是二進制的情形,事件發生 / 不發生的概率分別為 p/(1−p),任何只有兩個結果的隨機試驗都可以用兩點分布描述,拋擲一次硬幣的結果就可以視為等概率的兩點分布
● 二項分布:將滿足參數為 p 的兩點分布的隨機試驗獨立重復 n 次,事件發生的次數即滿足參數為 (n,p) 的二項分布,二項分布的表達式可以寫成
● 泊松分布:放射性物質在規定時間內釋放出的粒子數所滿足的分布,參數為 λλ 的泊松分布表達式為
當二項分布中的 n 很大且 p 很小時,其概率值可以由參數為 λ=np 的泊松分布的概率值近似
● 均勻分布:在區間 (a, b) 上滿足均勻分布的連續型隨機變量,其概率密度函數為
1 / (b - a), 這個變量落在區間 (a, b) 內任意等長度的子區間內的可能性是相同的
1 / (b - a), 這個變量落在區間 (a, b) 內任意等長度的子區間內的可能性是相同的
● 指數分布:滿足參數為 θ 指數分布的隨機變量只能取正值,其概率密度函數為
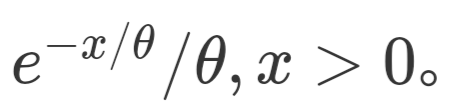
數分布的一個重要特徵是無記憶性:即 P(X > s + t | X > s) = P(X > t)
● 正態分布:參數為正態分布的概率密度函數為
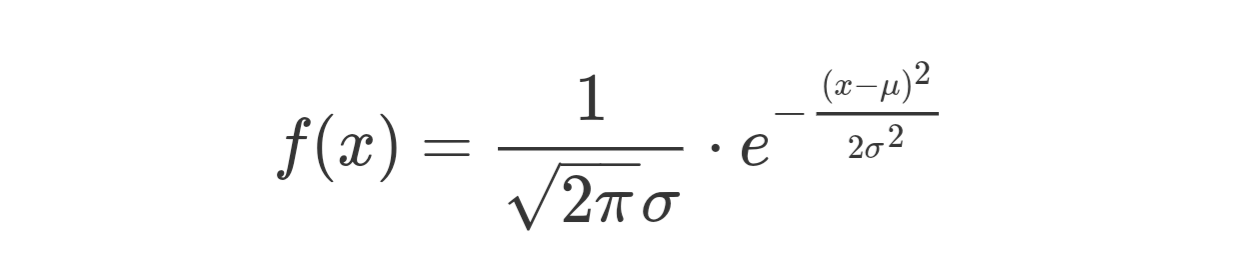
● 正態分布:參數為正態分布的概率密度函數為
當 μ=0,σ=1 時,上式稱為標準正態分布,正態分布是最常見最重要的一種分布,自然界中的很多現象都近似地服從正態分布
除了概率質量函數 / 概率密度函數之外,另一類描述隨機變量的參數是其數字特徵,數字特徵是用於刻畫隨機變量某些特性的常數,包括數學期望、方差和協方差
數學期望即均值,體現的是隨機變量可能取值的加權平均,即根據每個取值出現的概率描述作為一個整體的隨機變量的規律,方差表示的則是隨機變量的取值與其數學期望的偏離程度,方差較小意味著隨機變量的取值集中在數學期望附近,方差較大則意味著隨機變量的取值比較分散
數學期望和方差描述的都是單個隨機變量的數字特徵,如果要描述兩個隨機變量之間的相互關係,就需要用到協方差和相關係數,協方差度量了兩個隨機變量之間的線性相關性,即變量 Y 能否表示成以另一個變量 X 為自變量的 aX+b 的形式
根據協方差可以進一步求出相關係數,相關係數是一個絕對值不大於 1 的常數,它等於 1 意味著兩個隨機變量滿足完全正相關,等於 -1 意味著兩者滿足完全負相關,等於 0 則意味著兩者不相關,需要說明的是,無論是協方差還是相關係數,刻畫的都是線性相關的關係,如果隨機變量之間的關係滿足 Y=X2,這樣的非線性相關性就超出了協方差的表達能力
總結以上人工智慧必備的概率論基礎,著重於抽象概念的解釋而非具體的數學公式,其要點如下:
● 概率論關注的是生活中的不確定性或可能性
● 頻率學派認為先驗分布是固定的,模型參數要靠最大似然估計計算
● 正態分布是最重要的一種隨機變量的分布
● 貝葉斯學派認為先驗分布是隨機的,模型參數要靠後驗概率最大化計算
除了概率質量函數 / 概率密度函數之外,另一類描述隨機變量的參數是其數字特徵,數字特徵是用於刻畫隨機變量某些特性的常數,包括數學期望、方差和協方差
數學期望即均值,體現的是隨機變量可能取值的加權平均,即根據每個取值出現的概率描述作為一個整體的隨機變量的規律,方差表示的則是隨機變量的取值與其數學期望的偏離程度,方差較小意味著隨機變量的取值集中在數學期望附近,方差較大則意味著隨機變量的取值比較分散
數學期望和方差描述的都是單個隨機變量的數字特徵,如果要描述兩個隨機變量之間的相互關係,就需要用到協方差和相關係數,協方差度量了兩個隨機變量之間的線性相關性,即變量 Y 能否表示成以另一個變量 X 為自變量的 aX+b 的形式
根據協方差可以進一步求出相關係數,相關係數是一個絕對值不大於 1 的常數,它等於 1 意味著兩個隨機變量滿足完全正相關,等於 -1 意味著兩者滿足完全負相關,等於 0 則意味著兩者不相關,需要說明的是,無論是協方差還是相關係數,刻畫的都是線性相關的關係,如果隨機變量之間的關係滿足 Y=X2,這樣的非線性相關性就超出了協方差的表達能力
總結以上人工智慧必備的概率論基礎,著重於抽象概念的解釋而非具體的數學公式,其要點如下:
● 概率論關注的是生活中的不確定性或可能性
● 頻率學派認為先驗分布是固定的,模型參數要靠最大似然估計計算
● 正態分布是最重要的一種隨機變量的分布
● 貝葉斯學派認為先驗分布是隨機的,模型參數要靠後驗概率最大化計算
0 意見:
張貼留言